Калибровка¶
В задаче кредитного скоринга основной целевой переменной является факт выхода клиента в дефолт. С момента принятия решения по заявке на кредит до «созревания» целевой переменной проходят месяцы. Поэтому для обучения моделей используются данные с запаздыванием на существенной время. Иногда требуется добавить в модель эффекты по более актуальным данным, например, использую другие целевые переменные, «созревающие» быстрее.
В данном ноутбуке мы рассмотрим пример обучения логистичесокй регрессии для «долго созревающей» целевой переменной по последним данным по более «короткой» целевой переменной.
Выборка¶
Для начала сгенерируем выборку.
In [1]:
import pandas as pd
import numpy as np
from scipy.special import expit
np.random.seed(42)
n = 10000
df = pd.DataFrame()
df['logit_main'] = np.random.randn(2 * n) * 0.5 - 1
df.loc[:n-1, 'sample_date'] = np.random.choice(pd.date_range('2001-01-01', '2001-12-31'), n)
df.loc[n:, 'sample_date'] = np.random.choice(pd.date_range('2002-01-01', '2002-12-31'), n)
df.loc[:n-1, 'f'] = 0
df.loc[n:, 'f'] = np.random.binomial(1, 0.6, size=n)
df['logit'] = df['logit_main'] + 0.6 * df['f']
df['y_long'] = np.random.binomial(1, expit(df['logit']))
df['y_short'] = np.random.binomial(1, expit(2 * df['logit'] - 0.5))
df.head(2)
Out[1]:
| logit_main | sample_date | f | logit | y_long | y_short | |
|---|---|---|---|---|---|---|
| 0 | -0.751643 | 2001-10-15 | 0.0 | -0.751643 | 0 | 0 |
| 1 | -1.069132 | 2001-03-22 | 0.0 | -1.069132 | 0 | 0 |
В игрушечной выборке содержатся:
logit_main- признак, не меняющий своего влияния на целевые переменные со временемsample_date- датаy_short,y_long- «короткая» и «длинная» целевые переменныеf- признак, меняющий свою логику со временем
Визуализация выборки¶
In [2]:
import holoviews as hv
hv.extension('matplotlib')


In [3]:
from risksutils.visualization import distribution
distribution(df, 'f', 'sample_date', date_freq='W')
Out[3]:

Признак f меняет свое распределение.
Выборку условно можно разделить на:
- Старую – 2001 год
- Новую – 2002 год
Имитирую возможную ситуацию мы будем считать, что на старых данных у нас
есть «созревшая» «длинная» целевая переменная y_long, а вот на новых
данных ее значений – нет. При этом мы хотим по влиянию признака f на
«короткую» целевую переменную суметь понять, какое будет влияние на
«длиную», глядя на «новую» выборку.
Различие влияния на разных выборках¶
В нашей сгенерированнй выборке признак logit_main содержит основной
сигнал и на старых данных вероятность наступления события
y_long == 1 равна 1 / (1 + exp(-logit_main)). А вот на новых
данных из-за наличия признака f происходит смещение.
In [4]:
from risksutils.visualization import isotonic
df_old = df.query('sample_date <= "2001-12-31"').copy()
df_new = df.query('sample_date >= "2002-01-01"').copy()
df_old['prob'] = expit(df_old['logit_main'])
df_new['prob'] = expit(df_new['logit_main'])
iso_long_old = isotonic(df_old, 'prob', 'y_long').relabel('Old')
iso_long_new = isotonic(df_new, 'prob', 'y_long').relabel('New')
iso_long_old + iso_long_new
Out[4]:

На левой картине видно, что реальные значения частоты наступления
события (ступеньки на диаграмме) лежат практичеки на диагонали, а вот на
правой диаграмме по новой выборке виден эффект влияния признака f.
Мы хотим извлечь этот эффект без наличия целевой переменной по новой выборки, но используя значение «короткой» целевой переменной.
Наримуем такие же картинки для короткой целевой переменной.
In [5]:
iso_short_old = isotonic(df_old, 'prob', 'y_short').relabel('Old')
iso_short_new = isotonic(df_new, 'prob', 'y_short').relabel('New')
iso_short_old + iso_short_new
Out[5]:

Различие графиков тут так же есть, но влияние нашего прогноза не точное – левый график не лежит вблизи диагонали.
Чтобы по влиянию на короткую целевую переменную делать выводы о влиянии на длинную нужно для начала понимать соотношение между ними. Для этого мы будем использовать старые данные, на которых представлены обе переменные.
Соотношение между целевыми переменными¶
Получить соотношение можно многими способами. Мы постоим две модели для обеих целевых переменных на старых данных и пройдя по небольшой сетке посчитаем значения прогнозов.
В качестве модели возьмем логистическую регрессию, а признаком будет
logit_main, содержащим сильный сигнал. Так как логистическая
регрессия довольно скудный класс моделей, а мы хотим точнее определить
эффекты, то мы используем разбивку признака на интервалы с помощью
сплайнов.
Получится, что вместо двух коэффициентов (константа и коэффициент перед
признаком) мы будем искать коюффициенты для каждого интервала. Можно
сказать, что модель у нас получится кусочно линейная.
In [6]:
import statsmodels.formula.api as smf
model_long = smf.logit('y_long ~ bs(logit_main, df=3, degree=1)', df_old).fit(disp=0)
model_short = smf.logit('y_short ~ bs(logit_main, df=3, degree=1)', df_old).fit(disp=0)
grid = pd.DataFrame()
min_logit, max_logit = df_old.logit_main.min(), df_old.logit_main.max()
grid['logit_main'] = np.linspace(min_logit, max_logit, 500)
calibrations = pd.DataFrame()
calibrations['y_long'] = model_long.predict(grid)
calibrations['y_short'] = model_short.predict(grid)
calibrations.head(2)
Out[6]:
| y_long | y_short | |
|---|---|---|
| 0 | 0.052131 | 0.001640 |
| 1 | 0.052497 | 0.001666 |
В таблице указано поточечное соотношение между целевыми переменными. Можно изобразить его в виде графика.
In [7]:
%matplotlib inline
calibrations.plot(x='y_long', y='y_short', grid=True);
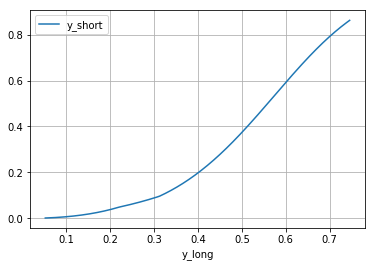
У функции isotonic есть возможность удобно вставить данный график,
только нужно указать, что мы считаем за прогноз - создать поле
predict.
In [8]:
calibrations['predict'] = calibrations['y_long']
isotonic(df_new, 'prob', 'y_short', calibrations_data=calibrations)
Out[8]:

Видно, что на новых данный частота наступления события y_short
оказывается выше, чем она должа быть судя по калибровке со старой
выборки.
Саму калибровку мы и используем для расчета модели по новым данным. Только нам необходимо её доопределить на всем интервале (0, 1). Для этого добавим пару строк в исходную таблицу с калибровками.
In [9]:
calibrations.loc[-1, :] = 0
calibrations.loc[-2, :] = 1
calibrations.sort_values('y_long', inplace=True)
calibrations.tail(2)
Out[9]:
| y_long | y_short | predict | |
|---|---|---|---|
| 499 | 0.745582 | 0.861817 | 0.745582 |
| -2 | 1.000000 | 1.000000 | 1.000000 |
Перекалибровка¶
В логистической регрессии прогноз вероятности события складывается из линейной комбинации признаков и сигмоидного преобразования
Помимо сигмоидного преобразования мы еще добавим кусочно линейное для расчета вероятности
In [10]:
from risksutils.models import recalibration
/home/docs/checkouts/readthedocs.org/user_builds/risksutils/conda/latest/lib/python3.5/site-packages/statsmodels-0.8.0-py3.5-linux-x86_64.egg/statsmodels/compat/pandas.py:56: FutureWarning: The pandas.core.datetools module is deprecated and will be removed in a future version. Please use the pandas.tseries module instead.
from pandas.core import datetools
In [11]:
model = recalibration(df=df_new, features=['f', 'logit_main'], target='y_short',
target_calibration='y_long', calibrations_data=calibrations)
model.summary()
Out[11]:
| Dep. Variable: | y_short | No. Observations: | 10000 |
|---|---|---|---|
| Model: | GLM | Df Residuals: | 9997 |
| Model Family: | Binomial | Df Model: | 2 |
| Link Function: | LogitAndInterpolation | Scale: | 1.0 |
| Method: | IRLS | Log-Likelihood: | -4201.4 |
| Date: | Sun, 01 Apr 2018 | Deviance: | 8402.8 |
| Time: | 00:39:11 | Pearson chi2: | 9.47e+03 |
| No. Iterations: | 100 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 0.0009 | 0.033 | 0.027 | 0.978 | -0.064 | 0.066 |
| f | 0.6306 | 0.031 | 20.124 | 0.000 | 0.569 | 0.692 |
| logit_main | 0.9624 | 0.031 | 31.192 | 0.000 | 0.902 | 1.023 |
Исходную сгенерированную зависимость мы восстановили
prob_long = 1 / (1 + exp(-(1 * logit_main + 0.6 * f))
Функция recalibration возвращает объект
GLMResultsWrapper
в нем сами параметры доступны через атрибут params.
In [12]:
model.params
Out[12]:
Intercept 0.000904
f 0.630633
logit_main 0.962426
dtype: float64
Так же доступна возможность применить модель через метод predict, но
тогда возвращаемое значение вероятности будет содержать и калибровку, то
есть прогнозировать y_short в нашем случае, а не y_long.
Использование сдвига¶
Если мы уверены в каких-нибудь коэффициентах, то мы можем не нестраивать
у них параметры, указав сдвиг offset в виде поля из таблицы.
Например, мы можем не настраивать коэффициент перед logit_main,
указав его в offset.
In [13]:
recalibration(df_new, ['f'], 'y_short', 'y_long', calibrations, offset='logit_main').summary()
Out[13]:
| Dep. Variable: | y_short | No. Observations: | 10000 |
|---|---|---|---|
| Model: | GLM | Df Residuals: | 9998 |
| Model Family: | Binomial | Df Model: | 1 |
| Link Function: | LogitAndInterpolation | Scale: | 1.0 |
| Method: | IRLS | Log-Likelihood: | -4202.1 |
| Date: | Sun, 01 Apr 2018 | Deviance: | 8404.2 |
| Time: | 00:39:11 | Pearson chi2: | 9.65e+03 |
| No. Iterations: | 10 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 0.0227 | 0.027 | 0.833 | 0.405 | -0.031 | 0.076 |
| f | 0.6383 | 0.031 | 20.565 | 0.000 | 0.577 | 0.699 |
В данном случае получили практически те же коэффициенты перед f и
константой.
Можно убрать из обучения и константу – use_bias = False.
In [14]:
model = recalibration(df_new, ['f'], 'y_short', 'y_long', calibrations, 'logit_main', use_bias=False)
model.summary()
Out[14]:
| Dep. Variable: | y_short | No. Observations: | 10000 |
|---|---|---|---|
| Model: | GLM | Df Residuals: | 9999 |
| Model Family: | Binomial | Df Model: | 0 |
| Link Function: | LogitAndInterpolation | Scale: | 1.0 |
| Method: | IRLS | Log-Likelihood: | -4202.4 |
| Date: | Sun, 01 Apr 2018 | Deviance: | 8404.9 |
| Time: | 00:39:12 | Pearson chi2: | 9.77e+03 |
| No. Iterations: | 7 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| f | 0.6610 | 0.015 | 44.456 | 0.000 | 0.632 | 0.690 |
Подсчет прогноза¶
Для получения прогноза на y_long можно руками собать из
коэффициентов predict_custom
In [15]:
predict_custom = expit(model.params['f'] * df_new['f'] + df_new['logit_main'])
А можно посчитать сначала predict_short через метод predict, а
затем выполнить обратное преобразования калибровки.
In [16]:
from scipy.interpolate import interp1d
calibration_func = interp1d(calibrations['y_short'], calibrations['y_long'])
predict_short = model.predict(df_new, offset=df_new['logit_main'])
predict_long = calibration_func(predict_short)
assert np.allclose(predict_custom, predict_long)
Второй способ может быть полезен для ситуации, когда признаков много или они задаются не списком, а формулой patsy.
Интерактивные диаграммы¶
При наличии различных целевых переменных, влиянии по времени полезно быстро визуализировать влияние прогноза.
In [17]:
hv.extension('bokeh')
from risksutils.visualization import InteractiveIsotonic

Заполним в нашу исходную таблицу пару прогнозов prob,
prob_calibrate
In [18]:
df['prob'] = expit(df['logit_main'])
df['prob_calibrate'] = calibration_func(model.predict(df, offset=df['logit_main']))
InteractiveIsotonic позволяет создавать набор связанных между собой
диаграмм:
isotonic– визуализация зависимости частоты наступления события от прогноза. Содержит виджеты для каждого выбора прогнозаpdimsи для выбора целевой переменнойtdims- диаграммы для категориальных полей, указанных в
gdims, и для временных, указанных вddims
In [19]:
diagram = InteractiveIsotonic(df, pdims=['prob', 'prob_calibrate'], tdims=['y_short', 'y_long'],
gdims=['f'], ddims=['sample_date'], calibrations_data=calibrations)
Обращаться к диаграммым можно как к атрибутам
In [20]:
diagram.isotonic
Traceback (most recent call last):
File "/home/docs/checkouts/readthedocs.org/user_builds/risksutils/conda/latest/lib/python3.5/site-packages/holoviews/plotting/util.py", line 251, in get_plot_frame
return map_obj[key]
File "/home/docs/checkouts/readthedocs.org/user_builds/risksutils/conda/latest/lib/python3.5/site-packages/holoviews/core/spaces.py", line 1073, in __getitem__
self._cache(tuple_key, val)
File "/home/docs/checkouts/readthedocs.org/user_builds/risksutils/conda/latest/lib/python3.5/site-packages/holoviews/core/spaces.py", line 1120, in _cache
self[key] = val
File "/home/docs/checkouts/readthedocs.org/user_builds/risksutils/conda/latest/lib/python3.5/site-packages/holoviews/core/ndmapping.py", line 520, in __setitem__
self._add_item(key, value, update=False)
File "/home/docs/checkouts/readthedocs.org/user_builds/risksutils/conda/latest/lib/python3.5/site-packages/holoviews/core/ndmapping.py", line 157, in _add_item
self._item_check(dim_vals, data)
File "/home/docs/checkouts/readthedocs.org/user_builds/risksutils/conda/latest/lib/python3.5/site-packages/holoviews/core/ndmapping.py", line 821, in _item_check
(self.__class__.__name__, type(data).__name__, self.type.__name__))
AssertionError: DynamicMap must only contain one type of object, not both Overlay and Curve.
Out[20]:
calibrations_data, то будут рисоваться так
же кривые калибровок.Если задать gdims и ddims, то можно строить диаграммы для
количества объектов. При этом на диаграммах с помощью тулзы BoxSelect
можно указать интересующую часть, тогда перестроятся все графики с
учетом условия.
In [21]:
%%opts Area [width=600]
diagram.sample_date
Out[21]:
In [22]:
diagram.f
Out[22]: